

Agnė Navickaitė-Klišauskienė, prof. Jurgis Pakerys, Vilniaus universiteto Filologijos fakultetas
Žodžių dažnis kalboje nevienodas – vienus ištariame ir išgirstame daugybę kartų per dieną, o kitų mums gali neprireikti ir visą gyvenimą. Patys dažniausi žodžiai yra abstraktūs ir trumpi – tai įvairūs įvardžiai, jungtukai, prielinksniai, pavyzdžiui: ji(s), ta(s), ši(s), ir, kad, į, iš ir pan. Tai suprantama – tokių žodžių reikia nuolat, jie net tame pačiame sakinyje gali pasikartoti.
Bet ką galėtume pasakyti apie labai retus lietuvių kalbos žodžius? Pirma – kad jų, kaip ir kitose kalbose, yra labai daug, jų sąrašas net į visą žurnalą netilptų. Antra – kad reti žodžiai gali nemažai pasakyti apie tai, kokie procesai vyksta mūsų kalboje, pavyzdžiui, kaip pasidarome naujus žodžius.
Kur galima rasti rečiausius žodžius?
Pirminė aplinka, kurioje gyvena žodis, yra tekstas – nesvarbu, ar rašytinis, ar sakytinis, todėl mokslininkai kuria dideles elektroninių tekstų sankaupas – tekstynus (korpusus, angl. corpus). Į juos dedami tekstai yra patys įvairiausi – nuo sausų administracinių dokumentų iki labai gyvų internetinių komentarų. Kuo daugiau ir kuo įvairesnių tekstų sukaupsime, tuo geriau galėsime įvertinti, kiek ir kokių žodžių lietuvių kalboje yra, kas ir kokiose situacijose juos ištaria ar parašo. Kartu išsiaiškinsime, kokie žodžiai dažniausi, o kokie – rečiausi. Be to, tekstų sankaupos naudingos ir tuo, kad jas galima panaudoti kuriant automatinio vertimo įrankius ir didelius kalbos modelius (angl. large language model, LLM), kurių pagrindu veikia „ChatGPT“ ir kitos panašios dirbtinio intelekto sistemos.
Tekstyno dydį nusako jame esančių žodžių formų skaičius, kurį turime skirti nuo pačių žodžių (kaip žodyno vienetų) skaičiaus. Pavyzdžiui, noriu, norėjau, spurgos, spurgų yra žodžių norėti ir spurga gramatinės formos, todėl čia matome keturias formas ir du savarankiškus žodžius – žodyno vienetus, kuriems tos formos priklauso. Virginijaus Dadurkevičiaus parengtuose Jungtinio lietuvių kalbos tekstyno žodžių ir jų formų sąrašuose yra maždaug 1,3 milijardo formų – tai šiuo metu didžiausia laisvai prieinama tokių duomenų sankaupa. Iš tų formų yra pavykę atpažinti maždaug 190 tūkstančių skirtingų žodžių, įskaitant ir tikrinius. Sakome „yra pavykę atpažinti“, nes tai nėra tokia jau paprasta užduotis – lygiai kaip žmogus ne visus žodžius bus girdėjęs ir supras, taip ir kompiuterinės programos ne visus juos geba atpažinti.

Šiuo metu lietuvių ir kitų kalbų tyrėjai dirba dviem kryptimis: stengiasi plėsti tekstynus, kad jie kuo geriau atspindėtų įvairių sričių kalbą, ir tobulina žodžių atpažinimo programas, kad jos pateiktų kuo išsamesnius žodžių sąrašus. Kuo geresnius tekstynus turėsime ir kuo tobuliau veiks žodžių atpažinimas, tuo tiksliau galėsime atsakyti į klausimą, kiek ir kokių žodžių dalyvauja lietuvių kalbos informacinėje apyvartoje.
Kaip atrodo priesagų varžybos?
Mes, šio teksto autoriai, bendradarbiaudami su Vytauto Didžiojo universiteto tyrėju V. Dadurkevičiumi, dabar analizuojame jau minėto Jungtinio lietuvių kalbos tekstyno duomenis. Vienas iš tyrimo aspektų – labai reti žodžiai, tekstyne aptinkami tik vieną kartą, dar vadinami hapaksais (senąja graikų kalba hapax legomenon reiškia ‘(tai, kas) vienąsyk pasakoma’). XX a. pabaigoje atliktuose inovatyviuose Haraldo Baayeno darbuose teigiama, kad atsižvelgiant į hapaksus galima įvertinti, kókios naujų žodžių sudarymo priemonės kalboje yra pačios aktyviausios. Tyrėjas atkreipė dėmesį į tai, kad pakankamai dideliuose tekstynuose reikšminga hapaksų dalis yra naujai pasidaryti žodžiai. Pavyzdžiui, jei rasime daug labai retų žodžių su ta pačia priesaga, tai bus signalas, kad ta priesaga laikytina produktyvia, nes ją žmonės dažnai pasitelkia kurdami naujus žodžius. Tačiau, kaip nurodo H. Baayenas ir kiti tyrėjai, visų hapaksų su naujais žodžiais jokiu būdu negalima tapatinti – tekstyne labai reti bus ir senstantys arba šiaip retai pasitaikantys žodžiai.
Kad suprastume, kaip veikia hapaksų signalas, panagrinėkime keletą pavyzdžių. Palyginti neseniai lietuvių kalboje atsirado skolinys kaituoti – ‘judėti vandens (ar kitu) paviršiumi naudojantis jėgos aitvaru – kaitu’. Kai tik šis veiksmažodis atėjo į mūsų gyvenimą, netrukus prireikė pasidaryti žodžius, kurie įvardytų atitinkamą veiksmą ir jį atliekantį asmenį. Tam reikalui veiksmažodis buvo konvertuotas į daiktavardžius: kaitav-im-as ir kaituo-toj-as, kaituo-toj-a. Sudarydami šiuos žodžius, žmonės pasitelkė modifikatorius – priesagas -im-as ir -toj-as, -a.
Šiems modifikatoriams išsiaiškinti specialiai pasirinkome naują veiksmažodį – iš jo padarytų daiktavardžių lietuvių kalboje anksčiau nebuvo, todėl žmonės savo kalbinėje sąmonėje turėjo aktyvinti tam tikras priesagas, tikėtina, produktyvias – tokias, su kuriomis sudaromi nauji žodžiai. Dabar pažiūrėkime, ką apie šias priesagas sako jų hapaksų signalas, ir palyginkime su kitomis tą pačią funkciją atliekančiomis priesagomis (1 pav.).
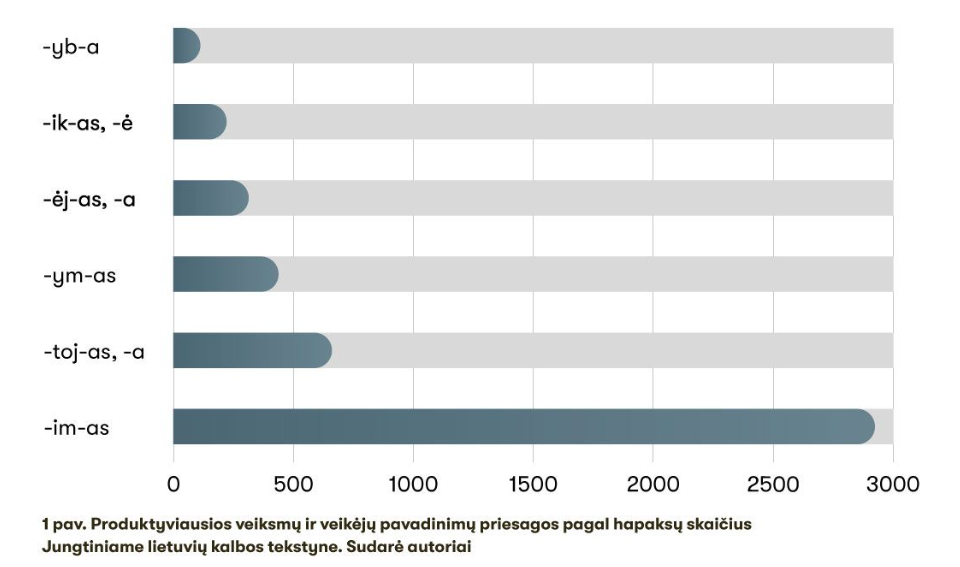
Minėtosios priesagos – -im-as ir -toj-as, -a – mūsų tekstyne turi daugiausia hapaksų ir akivaizdžiai lenkia artimiausias konkurentes – veiksmų priesagą -ym-as ir veikėjų priesagas -ėj-as, -a ir -ik-as, -ė. Hapaksų skaičiai šiuo atveju ne tik patvirtina mūsų lingvistinę intuiciją ir gramatikų teiginius, kad tos priesagos produktyvios, bet ir – o tai labai svarbu – leidžia produktyvumą įvertinti kiekybiškai – kiek vienos priesagos produktyvesnės už kitas.
Kad įsitikintume hapaksų ypatingumu, pasižiūrėkime į keletą pavyzdžių iš mūsų tekstyno: [Valdovų rūmų] atstatymo sustabdymai ir vėl atstabd-ym-ai; naujų indėlių nebedraud-im-as visai tikėtinas; inteligentiški zuokiniai besisavin-toj-ai susidūrė su tiesmukišku viktoro jamimu; Šie smulkūs atsivež-ėj-ai tikrai negali paveikti monopolisto; tiems buduliniams [kandidatūrų] atsiėm-ik-ams reikia uždrausti dalyvavimą rinkimuose. Visais atvejais matyti, kad žmogui reikėjo tam tikroje situacijoje šalia veiksmažodžio susikurti daiktavardį, kurio kalboje dar nebuvo, o tam buvo pasitelktos produktyvios žodžių sudarymo priemonės – mūsų ką tik minėtos priesagos.
Neplanuoti atradimai
Nagrinėdami hapaksus ir kitus retus žodžius galime ne tik gauti produktyvumo signalų, bet ir patvirtinti retas kalbinių elementų kombinacijas. Pavyzdžiui, norėdami pasakyti, kad veiksmas tam tikru aspektu ribotas, prie veiksmažodžio lietuvių kalboje galime pridėti priešdėlį te-. Štai pora iliustracijų iš mūsų tekstyno: Vyrai mažai te-sirūpina sveikata; Va, opozicija tik savimi te-sirūpina. Bet pasvarstykime: ar priešdėlį te- galėtume rasti ir veiksmo pavadinime su priesaga -im-as?
Tokia tikimybė yra, nes gerai žinoma, kad produktyvūs veiksmų pavadinimai įvairiose kalbose savo struktūra ir funkcijomis priartėja prie veiksmažodžio formų, todėl nemaža dalis veiksmažodžio elementų (mūsų atveju – priešdėlis te-) galėtų pereiti ir į veiksmo pavadinimus. Šiuo atveju matome, kad lingvistikoje, panašiai kaip ir kituose moksluose, tam tikrus elementus ir jų kombinacijas galime nuspėti teoriškai, bet norėdami tą spėjimą patvirtinti turime remtis didelės apimties tekstynais arba kitais duomenų šaltiniais, pavyzdžiui, psicholingvistiniais eksperimentais.
Mūsų tyrimo atveju, tiesa, išankstinio spėjimo net nebuvo – tiesiog stengėmės surinkti kuo daugiau duomenų ir – vėlgi panašiai, kaip ir kitiems mokslininkams nutinka – atsitiktinai radome minėtą kombinaciją patvirtinančios medžiagos – tris veiksmų pavadinimus su priešdėliu te-: tesirūpinimas, tepripažinimas, tesurinkimas. Paskutiniai du žodžiai yra hapaksai, o pirmojo daiktavardžio vartosenos pavyzdys į tekstyną pateko du kartus, štai jo fragmentas: protestas buvo prieš dabartinės valdžios politiką aplamai – didelę bedarbystę, pensijų mažinimus, aroganciją, tesirūpinimą tik biudžetininkų gerove.
Ar lengva pagauti retą žodį?
Kiek tekstyne rasime retų žodžių, priklauso nuo to, kaip sėkmingai juos atpažino specialios programos. Pirminį – visiškai žalią – tekstyną sudaro potencialios žodžių formos (raidžių sekos) ir įvairūs papildomi elementai – skaičiai, simbolių eilutės ir panašiai, todėl, norėdami gauti to tekstyno žodžių sąrašą (žodyną), turime jį specialiai paruošti. Tokius sąrašus rengia kompiuterinės programos, sugebančios atpažinti, kokiam žodžiui priklauso tekstyne aptinkamos konkrečios gramatinės formos.
Žodžių atpažinimas tekstyne vadinamas lemavimu, o jį atliekančios programos – lematizatoriais. Dažniausiai lematizatoriai gerai atpažįsta dažnesnius žodžius, o retesnieji gali būti netinkamai interpretuoti arba visai neatpažinti. Todėl tokiems tyrimams, kuriuos dabar atliekame, labai svarbi atviroji prieiga: turi būti pasiekiami ir tekstyno formų, ir lemų (atpažintų žodžių) sąrašai, taip pat turi būti kuo išsamiau aprašytas lematizatorius. Tik tada galėsime suprasti, kiek sėkmingas buvo tekstyno lemavimas, ir nuspręsti, kokius darbus reikia atlikti papildomai, kad retų žodžių signalas būtų kuo patikimesnis.

Pavyzdžiui, mūsų atveju pirminis automatinis lemavimas atpažino 583 potencialius hapaksus su priesaga -im-as ir tik 22 hapaksus su priesagomis -toj-as, -toj-a. Nujautėme, kad dideliam tekstynui šie skaičiai gerokai per maži, todėl atlikome papildomą pusiau rankinį lemavimą – automatiškai atrinkome visas mus dominančių galimų žodžių formas, jas jungėme į lemas, o vėliau patikrinome rankiniu būdu – atmetėme programos padarytas klaidas. Po papildomo lemavimo hapaksų skaičiai reikšmingai išaugo: priesagą -im-as turėjo jau 2855 hapaksai, o priesagas -toj-as ir -toj-a – iš viso 646 hapaksai.
Tikimės, kad artimiausiu metu savo darbus galėsime pratęsti ir pradėsime tirti būdvardinius hapaksus, o vėliau imsimės ir veiksmažodžių. Kartu stebėsime, kaip plėtojami lietuvių kalbos tekstynai ir lematizatoriai – kuo jie bus geresni, tuo daugiau galėsime pasakyti apie dabartinę lietuvių kalbos struktūrą ir jos artimiausią ateitį.
Projektas „Lietuvių kalbos priesaginių daiktavardžių darybinis produktyvumas Jungtinio tekstyno duomenimis“ finansuotas Lietuvos mokslo tarybos (LMTLT), sutarties nr. S-LIP-22-6.